Fine-Tuning Alpaca: Enabling Communication between LLMs on my M1 Macbook Pro
In this blog post, I will share a piece of the work I created for my thesis, which focused on analyzing student-tutor dialogues and developing a text generation system that enabled communication between a student chatbot and a tutor chatbot. This system allowed me to test critical hypotheses without the need for human intervention.
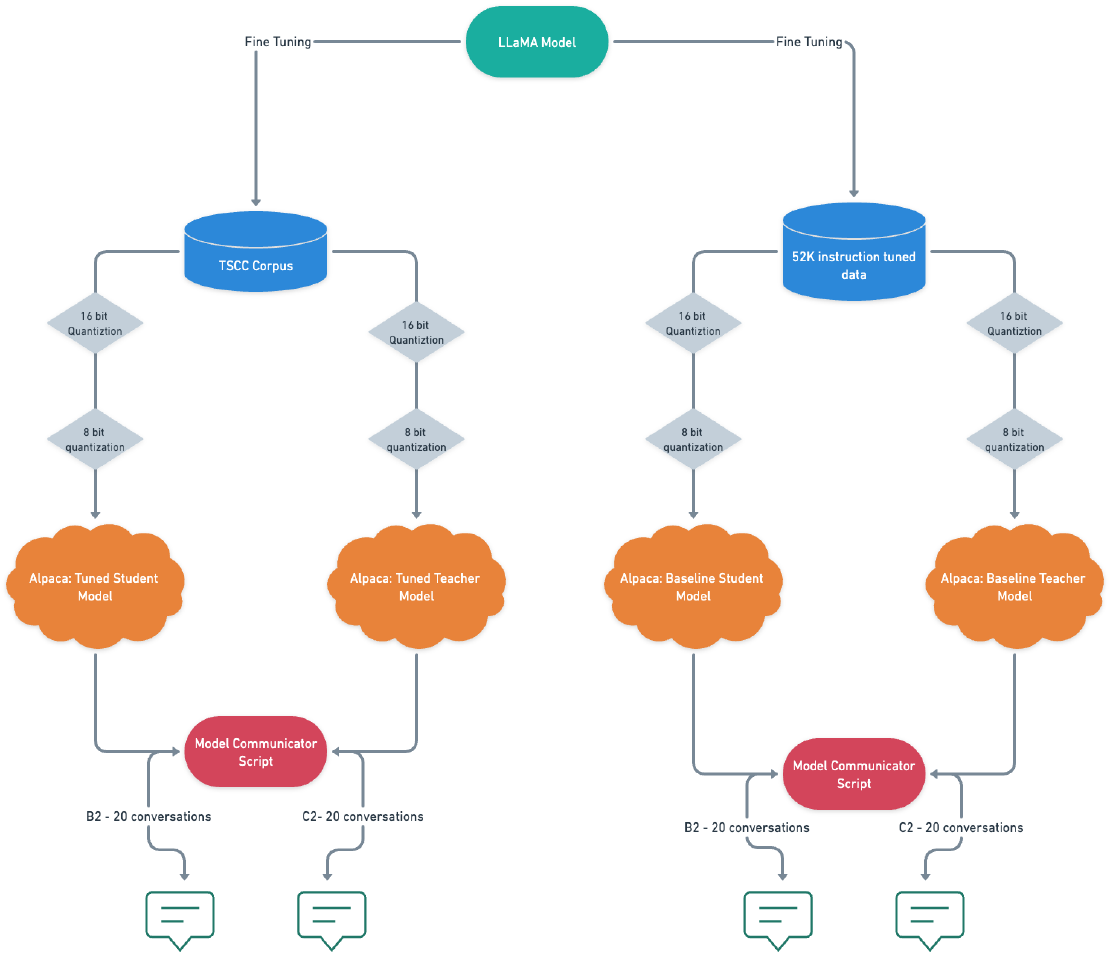
To enable LLM’s (Language Models) to communicate with each other, extensive research on quantization techniques and the latest advancements in NLP (Natural Language Processing) was crucial. The figure below shows the architectural diagram of the system built to enable communication between two finetuned Alpaca models as well as base Alpaca models.
Code for the model communicator is present in my GitHub repository at: https://github.com/nandangrover/model-communicator
Choosing the Right Model
While we will be going through with LLaMA/Alpaca model, it is crucial to consider all the existing LLM’s while making this choice. When selecting a model for text generation, several factors need to be considered:
-
Adequate context capacity: The classifiers I built required a minimum of 20 conversation turns to effectively assess a student’s ability level. Therefore, the chosen model needed to have enough context capacity to accommodate this requirement.
-
Dual functionality: The model should be capable of functioning as both a student and a tutor, allowing for automated interactions and evaluation between two instances of the model.
-
Low memory capacity: It was essential for the model to have low memory requirements to enable the simultaneous operation of two models using standard CPU and hardware.
-
Coherence, quality, and consistency: The text generated by the model should be coherent, of high quality, and consistent with the given context.
-
Limited data: Despite having a limited amount of data, the fine-tuned model should demonstrate improved text generation abilities. Although the TSCC corpus used in this research was extensive, it was not as comprehensive as the corpora used to train some LLMs.
-
**Open Source: **The model should be available as open-source software, allowing free access and usage. Additionally, the model weights should be accessible for academic purposes and fine-tuning.
Based on these characteristics, weconducted an exploratory analysis of various text generation models that aligned with our criteria. The results of this analysis are presented in the table below.
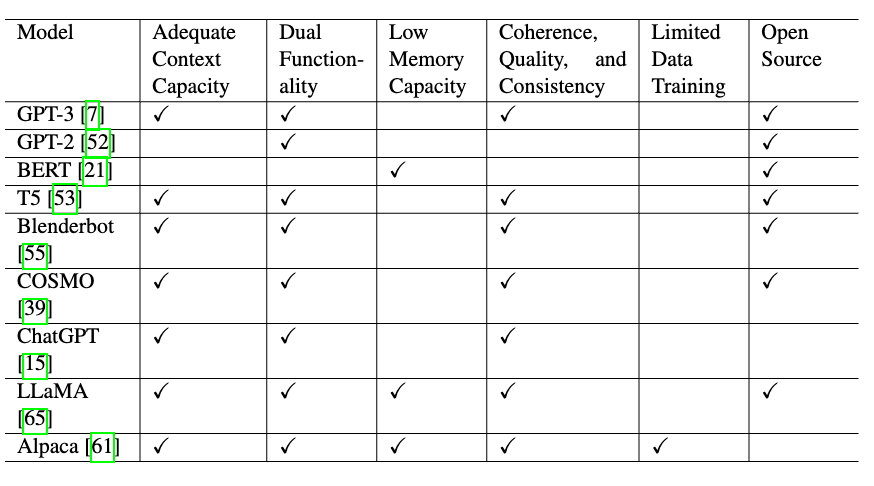
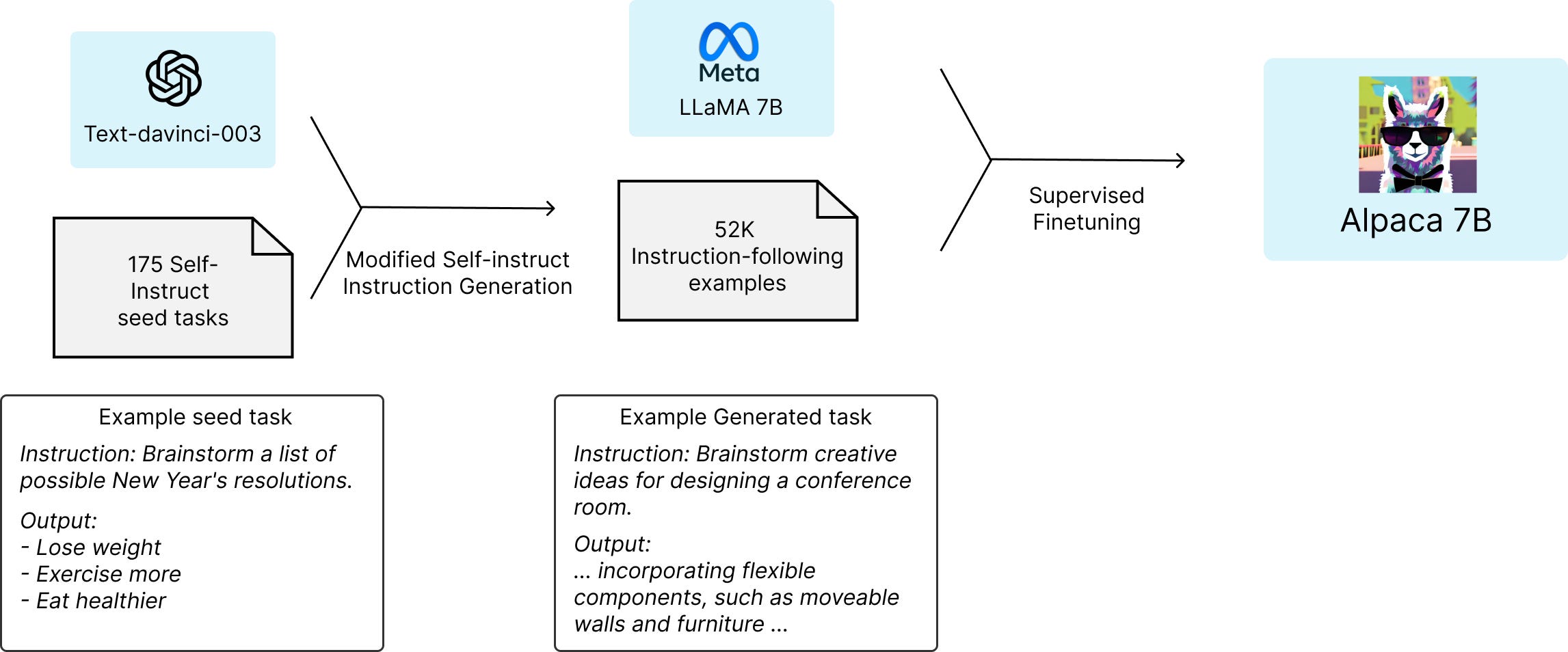
After extensive analysis, we determined that the Alpaca model, developed by Taori et al. [1], fulfilled all the criteria we sought in a generation model. Alpaca is a fine-tuned version of the 7B LLaMA model [2], trained on 52,000 instances of instruction-following data using the techniques described in the Self-Instruct paper [3], with some modifications. Initial human evaluations indicated that the Alpaca 7B model performed similarly to the text-davinci-003 model [4] on the Self-Instruct instruction-following evaluation suite [5].
Although the code for the Alpaca model is open source, its model weights are not. In order to utilize Alpaca’s text generation capabilities, we will replicate the experiment detailed in by Taori et al. [1] using the LLaMA weights and 52k instruction data to recreate Alpaca weights. We will then employ this training methodology to train both a Student and a Teacher Model.
Model and Data Foundations
In our research, we aim to create three models: Alpaca Base, Student Alpaca, and Teacher Alpaca. The Alpaca Base model acts as the control group or baseline model, replicating the experiment conducted by Taori et al. Its purpose is to help us evaluate the effectiveness of the fine-tuned Student and Teacher models. The architecture of the Alpaca model, as presented by Taori et al., can be seen in Figure 3.
The Student Alpaca model is developed by applying the techniques used by Taori et al. to fine-tune the 7B LLaMA model. We obtain the necessary training data for this model through the data curation process described in the previous section, specifically the student data highlighted in green in Figure 4.

Similarly, the Teacher Alpaca model is also fine-tuned using the methods outlined by Taori et al. on the 7B LLaMA model. We acquire the data for this model through the same data curation process, with the teacher data originating from the process highlighted in red in Figure 4.
Fine-Tuning
To fine-tune our models, we utilize Alpaca Lora, a technique that leverages Low-rank adaptation (LoRA). Compared to previous methods, LoRA offers several advantages, including faster processing time, lower memory consumption, and smaller output size in the order of megabytes instead of gigabytes. Additionally, LoRA allows for the combination of multiple fine-tuned models at runtime. These features enable cost-effective and efficient model fine-tuning, even on modest hardware such as low-spec GPUs like the NVIDIA T4 or consumer GPUs like the 4090.
To expedite the fine-tuning process, we employ Alpca Lora. With the help of Google Cloud Computing, which provides access to powerful hardware configuration, we achieve significant training time reduction, completing our fine-tuning in just 3.5 hours. The hardware configuration includes 1 NVIDIA A100-SXM4–40GB GPU, 12 vCPUs, and 85GB of RAM.
The utilization of Alpaca Lora and LoRA in our fine-tuning process demonstrates the efficiency and cost-effectiveness of this method in model training. Our results showcase the potential of utilizing modest hardware for complex machine learning tasks, opening doors for further advancements in the field.
The below section highlights the steps taken to fine tune using Alpaca Lora.
Fine-tuning using Alpaca Lora
Step 1: Clone the Alpaca-LoRA repo
We’ve created a fork of the original Alpaca-LoRA repo that adds support for Cog. Cog is a tool to package machine learning models in containers and we’re using it to install the dependencies to fine-tune and run the model.
Clone the repository using Git:
git clone https://github.com/daanelson/alpaca-lora
cd alpaca-lora
Step 2: Get LLaMA weights
LLaMA wights can be found at Google Drive Folder under the chatbot/llama folder. Put your downloaded weights in a folder called unconverted-weights. The folder hierarchy should look something like this:
unconverted-weights
├── 7B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ └── params.json
├── tokenizer.model
└── tokenizer_checklist.chk
Convert the weights from a PyTorch checkpoint to a transformers-compatible format using this command:
cog run python -m transformers.models.llama.convert_llama_weights_to_hf \
--input_dir unconverted-weights \
--model_size 7B \
--output_dir weights
You final directory structure should look like this:
weights
├── llama-7b
└── tokenizermdki
Step 3: Install Cog
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)"
sudo chmod +x /usr/local/bin/cog
Step 4: Fine-tune the model
The fine-tuning script is configured by default to work on less powerful GPUs, but if you have a GPU with more memory, you can increase MICRO_BATCH_SIZE to 32 or 64 in finetune.py .
We need to place our curated dataset generated using Data_Curation_and_Quantization.ipynb in the root directory and edit DATA_PATH in finetune.py to point to this dataset.
Run the fine-tuning script:
cog run python finetune.py
This takes 3.5 hours on a 40GB A100 GPU, and more than that for GPUs with less processing power.
Quantization
Quantization techniques have gained significant traction in reducing the memory footprint and inference latency of neural network models. These techniques involve representing model parameters using fewer bits. Recent research indicates that 4-bit precision offers a favorable trade-off between model size and accuracy. In this blog, we explore the implementation of quantization using llama.cpp, a software package developed by Gerganov [4]. This package allows us to run the LLaMA model with 4-bit integer quantization on a MacBook. Leveraging quantization enables us to simultaneously run two models and make use of the Model Communication framework.
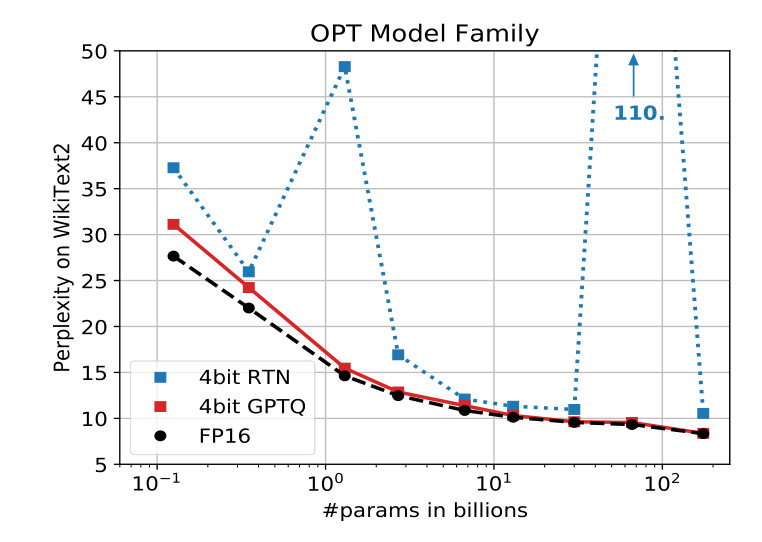
The llama.cpp package employs GPTQ quantization, which is a state-of-the-art method for achieving negligible output performance loss. It surpasses prior techniques for 4-bit, 3-bit, and 2-bit quantization, as well as uncompressed fp16 inference. GPTQ can compress GPT models with 175 billion parameters in just four GPU hours, reducing the bitwidth to 3 or 4 bits per weight while maintaining accuracy levels close to the uncompressed baseline. The effectiveness of GPTQ can be observed in Figure 5, where the perplexity of the OPT model family remains consistent for both FP16 and 4-bit quantized versions.
To implement model quantization, refer to the instructions in the below section. By adopting the aforementioned quantization method, llama.cpp successfully compressed the LLaMA model from 13 GB to a more manageable 3.9 GB. This reduction in size allows for inference on a moderately priced CPU and facilitates the use of the script detailed in Section 3 of this article. Notably, the script runs smoothly on a MacBook Pro with an M1 chip, showcasing the efficiency of the quantization approach.
Data Curation and Quantization using llama.cpp
The Data Curation and Quantization sub-system involves the curation of data for fine-tuning and the quantization of the fine-tuned models. The code for this sub-system can be found in the Text Generation System folder.
The notebook called Data_Curation_and_Quantization.ipynb contains the code for curating the data required for fine-tuning and for quantization of models after following the steps in Fine-tuning using Alpaca Lora. Additionally, it contains the code for quantizing the fine-tuned models.
The process for quantizing the fine-tuned Alpaca model is detailed below.
Step 1: Clone the llama.cpp Repository
To begin, clone the llama.cpp repository using Git. Navigate to the cloned directory using the following command:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Step 2: Obtain the Original LLaMA Model Weights
Download the original LLaMA [65] model weights from the provided Google form and place them in the ./models directory. Verify that the files are present in the directory using the following command:
ls ./models 65B 30B 13B 7B tokenizer_checklist.chk tokenizer.model
Step 3: Install Python Dependencies
Install the required Python dependencies using the following command:
python3 -m pip install -r requirements.txt
Step 4: Consolidate Alpaca Model Weights
Run the consolidate_alpaca method present in the Data_Curation_and_Quantization.ipynb notebook. The consolidate_alpaca function is used to merge the weights of the two language models (LLAMA and PeftModel) to create a single model that has the improved performance of PeftModel while retaining the overall architecture of LLAMA. The function initializes the LLAMA tokenizer, loads the LLAMA language model, and then loads a second language model called PeftModel, which is trained on top of the LLAMA language model to improve its performance. The function then merges the weights of some layers of the PeftModel with the corresponding layers of the LLAMA model.
Step 5: Convert the Model to GGML FP16 Format
Convert the 7B model to GGML FP16 format using the provided convert.py script. Use the following command:
python3 convert.py models/7B/
Step 6: Quantize the Model to 4-Bits
Quantize the model to 4-bits using the provided quantize script with the q4_0 method. Run the following command:
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin
q4_0
Model Communicator
In our pursuit of seamless communication with Alpaca models, we have developed the Model Communicator, a powerful Python library. This library acts as a bridge between the llama.cpp binary and the baseline and tuned Alpaca models, streamlining the interaction process. In this section, we will explore the key features and scripts that make up the Model Communicator and delve into the curated contextual data for optimal performance. Figure 6 shows the architecture of the Model Communicator subsystem.

The Core Scripts: The Model Communicator library consists of three primary scripts that work together to ensure efficient communication:
-
Model_communicator.py: This script serves as the central controller, responsible for receiving input context, managing spawned subprocesses, and interfacing with Alpaca Turbo. It acts as the command center for communication.
-
Alpaca_turbo.py: This script plays a crucial role in communicating with the Alpaca model. It employs sophisticated string manipulation techniques to process the output of piped subprocesses and relay it back to the Model Communicator. Here, the magic happens!
-
Interact.py: This script acts as a wrapper class around the Python process, providing additional utility functions for effectively managing input and output to the process. It simplifies the communication workflow.
Dialogue Simulation and running the communicator
The Model Communicator subsystem facilitates communication between the fine-tuned Student and Tutor models, as well as between the base Student and Tutor models. It achieves this through the use of binaries extracted from the llama.cpp library, which were utilized to quantize the tuned Alpaca models. The fine tuned or base alpaca models must be added to the models directory prior to running the script. The code for this subsystem is present in my GitHub repository .
To execute the script, the following command should be used:
python3 model_communicator.py B1 base
Here, the first argument refers to the grade, and the second argument specifies the type of model to be used, i.e., the base or fine-tuned model for communication. Note that if a conversation for a particular context has already been generated, it cannot be regenerated unless it is first deleted from the results folder. Additionally, the binaries for running this in macOS and Linux are present in bin folder. In order to run this in Windows, binaries specific to Windows need to be installed using llama.cpp [4]. The process of generating a single conversation can take up to an hour. Moreover, the system incorporates a concept of partial context, which allows for the recording of previously generated conversations up until a certain point in the event of the model getting stuck. This feature enables the restarting of the dialogue simulation from the saved checkpoint by restarting the python process.
Conclusion
In conclusion, we have highlighted the process of running two Language Models (LLMs) on an M1 Macbook Pro using LLaMa and Alpaca. The focus was on analyzing student-tutor dialogues and developing a text generation system that allowed for automated communication between a student chatbot and a tutor chatbot. Through extensive research, careful consideration of model characteristics, fine-tuning, and quantization techniques, the Alpaca model emerged as the most suitable choice for this task. The use of Alpaca Lora and LoRA for fine-tuning showcased the efficiency and cost-effectiveness of the training process, even on modest hardware. Additionally, the implementation of model quantization using llama.cpp enabled the simultaneous operation of two models and efficient utilization of the Model Communication framework. The Model Communicator library served as a powerful tool in streamlining the interaction process between the models, facilitating seamless communication. This work demonstrates the potential and advancements in utilizing LLMs for automated dialogues and opens doors for further research and development in the field.
References
-
Rohan Taori et al. Stanford Alpaca: An Instruction-following LLaMA model. https:/ /github.com/tatsu-lab/stanford_alpaca. 2023
-
tloen. tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware. GitHub, Apr. 2023. URL: https://github.com/tloen/alpaca-lora (visited on 04/12/2023).
-
Hugo Touvron et al. LLaMA: Open and Efficient Foundation Language Models. arXiv.org, 2023. URL: https://arxiv.org/abs/2302.13971
-
ggerganov. ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++. GitHub, Apr. 2023. URL: https://github.com/ggerganov/llama.cpp
Related Posts
Text Classification in NLP using Cross Validation and BERT
In natural language processing, text categorization tasks are common (NLP). Depending on the data they are provided, different classifiers may perform better or worse (eg.
Read more
Building a CI Pipeline using Github Actions for Sharetribe and RoR
Continuous Integration (CI) is a crucial part of modern software development workflows. It helps ensure that changes to the codebase are regularly integrated and tested, reducing the risk of introducing bugs and maintaining a high level of code quality.
Read more
Exploring if Large Language Models possess consciousness
As technology continues to advance, the development of large language models has become a topic of great interest and debate. These models, such as OpenAI’s GPT-4, are capable of generating coherent and contextually relevant text that often mimics human-like language patterns.
Read more